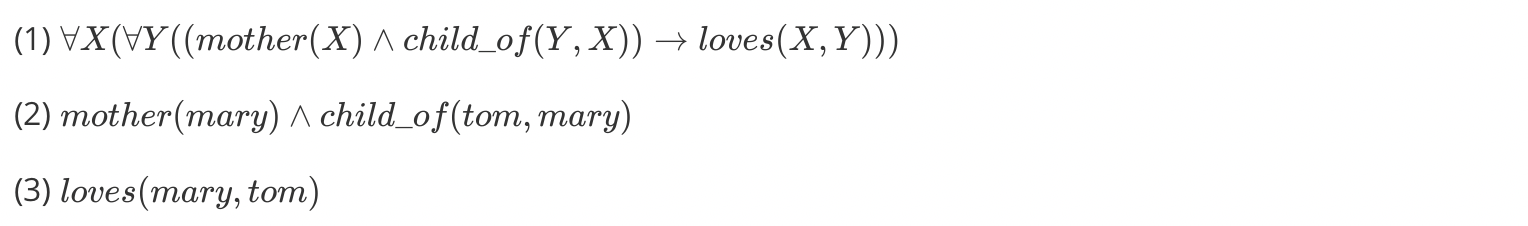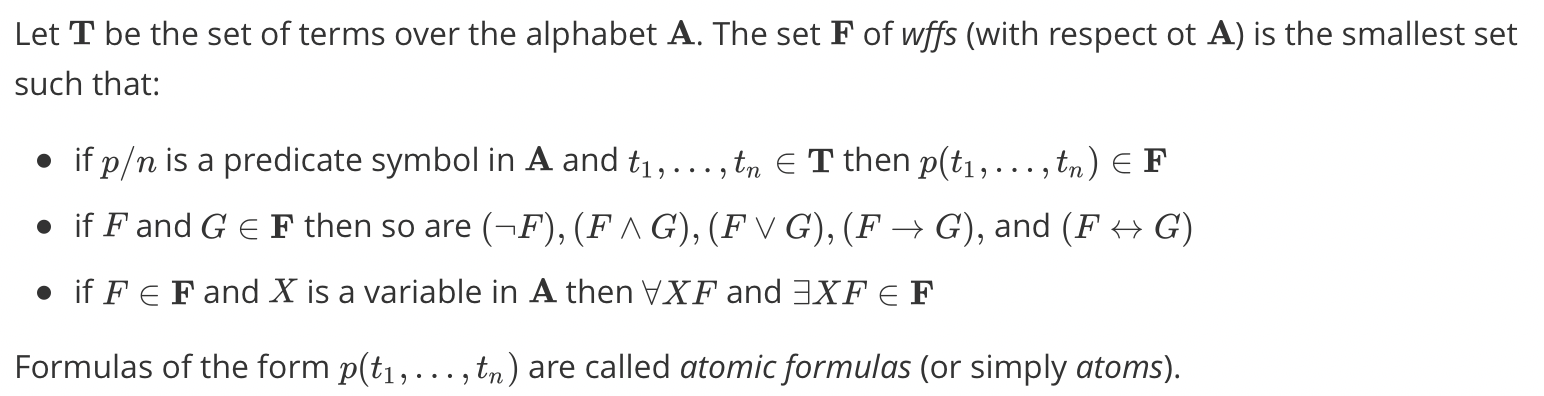The Least Herbrand Model
Definite programs can only express positive knowledge - both facts and rules say which elements of a structure are in a relation, but they do not say when the relations do not hold. Moreover, every definite program has a well defined least model. Intuitively this model reflects all information expressed by the program and nothing more.
Definition (Herbrand universe, Herbrand base)
Let $\bold{A}$ be an alphabet containing at least one constant symbol. The set $\bold{U_A}$ of all ground terms constructed from functors and constants in $\bold{A}$ is called the Herbrand universe of $\bold{A}$. The set $\bold{B_A}$ of all ground, atomic formulas over $\bold{A}$ is called the Herbrand base of $\bold{A}$.
The Herbrand universe and Herbrand base are often defined for a given program.
Example
Consider the following definite program $P$:
$$
odd(s(0)).\
odd(s(s(X)))\leftarrow odd(X).
$$
The program contains one constant (0) and one unary functor (s). Consequently the Herbrand universe looks as follows:
$$
\bold{U_P}={0, s(0), s(s(0)),s(s(s(0))),…}
$$
Since the program contains only one (unary) predicate symbol (odd) it has the following Herbrand base:
$$
\bold{B_P}={odd(0),odd(s(0)), odd(s(s(0))),…}
$$
Example
Consider the following definite program $P$: